
Forschung
The fields of machine learning and data engineering have gained a lot of attention over recent years. One of the reasons for this phenomenon is the fact that the data volumes have increased dramatically during the last decade. This is the case, for instance, in astronomy, where current and upcoming projects like the Sloan Digital Sky Survey (SDSS) or the Large Synoptic Sky Telescope (LSST) gather and will gather data in the tera- and petabyte range. For such projects, the sheer data volume renders a manual analysis impossible, and this necessitates the use of automatic data analysis tools. The corresponding data-rich scenarios often involve a large number of patterns (e.g. number of images) and/or a large number of dimensions (e.g. pixels per image). Further, a general lack of "labeled data" can often be observed, since the manual interaction with experts can be very time-consuming. Dealing with these situations usually requires the adaptation of standard data analysis techniques and this is one of the main objectives of our group.
Large-Scale Data Science
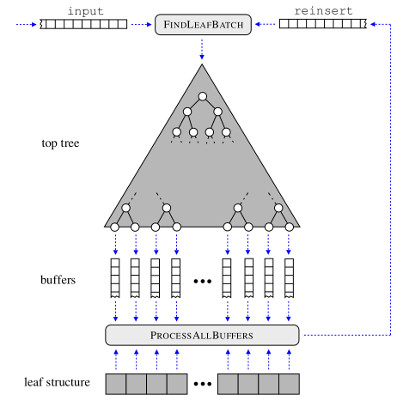 Data science techniques aim at “extracting” knowledge in an automatic manner and have been identified as one of the key drivers for discoveries and innovation. Our current research aims at the use of "cheap"' massively-parallel implementations to reduce the practical runtime of existing approaches. In contrast to conventional architectures, such modern systems are based on a huge amount of "small" specialized compute units, which are well-suited for massively-parallel implementations. The adaptation of data mining and machine learning techniques to such special hardware architectures has gained considerable attention during the last years. In case one can successfully adapt an approach to the specific needs of such systems, one can often achieve a significant runtime reduction (at much lower costs compared to the ones induced by traditional parallel computing architectures).
Data science techniques aim at “extracting” knowledge in an automatic manner and have been identified as one of the key drivers for discoveries and innovation. Our current research aims at the use of "cheap"' massively-parallel implementations to reduce the practical runtime of existing approaches. In contrast to conventional architectures, such modern systems are based on a huge amount of "small" specialized compute units, which are well-suited for massively-parallel implementations. The adaptation of data mining and machine learning techniques to such special hardware architectures has gained considerable attention during the last years. In case one can successfully adapt an approach to the specific needs of such systems, one can often achieve a significant runtime reduction (at much lower costs compared to the ones induced by traditional parallel computing architectures).
- Gieseke, F., Rosca, S., Henriksen, T., Verbesselt, J., & Oancea, C. (2020). Massively-Parallel Change Detection for Satellite Time Series Data with Missing Values. In Proceedings of the International Conference on Data Engineering (ICDE), Dallas, USA. (Accepted)
- Gieseke, F., & Igel, C. (2018). Training Big Random Forests with Little Resources. In Guo, Y., & Farooq, F. (Eds.), Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2018, London, UK, August 19-23, 2018 (pp. 1445–1454). ACM.
- Gieseke, F., Oancea, C., & Igel, C. (2017). bufferkdtree: A Python library for massive nearest neighbor queries on multi-many-core devices. Knowledge Based Systems, 120, 1–3.
- Gieseke, F., Heinermann, J., Oancea, C., & Igel, C. (2014). Buffer k-d Trees: Processing Massive Nearest Neighbor Queries on GPUs. In Proceedings of the 31th International Conference on Machine Learning (ICML), Beijing, China, 172–180.
Big Data Applications
 Modern telescopes and satellites gather huge amounts of data. Current catalogs, for instance, contain data in the terabyte range; upcoming projects will encompass petabytes of data. On the one hand, this data-rich situation offers the opportunity to make new discoveries like detecting new, distant objects. On the other hand, managing such data volumes can be very difficult and usually leads to problem-specific challenges. Machine learning techniques have been recognized to play an important role for upcoming surveys. Typical tasks in astronomy are, for instance, the classification of stars, galaxies, and quasars, or the estimation of the redshift of galaxies based on image data. Appropriate models are already in use for current catalogs. However, obtaining high-quality models for specific tasks can still be a very challenging task. We are involved in the development of redshift estimation models (e.g., regression models) for so-called quasi-stellar radio sources (quasars), which are among the most distant objects that can be observed from Earth. To efficiently process the large data volumes, we make use of spatial data structures (like k-d-trees), which can be applied for various other tasks as well. Current work also involves the application of deep learning models to, e.g., detect supernovae.
Modern telescopes and satellites gather huge amounts of data. Current catalogs, for instance, contain data in the terabyte range; upcoming projects will encompass petabytes of data. On the one hand, this data-rich situation offers the opportunity to make new discoveries like detecting new, distant objects. On the other hand, managing such data volumes can be very difficult and usually leads to problem-specific challenges. Machine learning techniques have been recognized to play an important role for upcoming surveys. Typical tasks in astronomy are, for instance, the classification of stars, galaxies, and quasars, or the estimation of the redshift of galaxies based on image data. Appropriate models are already in use for current catalogs. However, obtaining high-quality models for specific tasks can still be a very challenging task. We are involved in the development of redshift estimation models (e.g., regression models) for so-called quasi-stellar radio sources (quasars), which are among the most distant objects that can be observed from Earth. To efficiently process the large data volumes, we make use of spatial data structures (like k-d-trees), which can be applied for various other tasks as well. Current work also involves the application of deep learning models to, e.g., detect supernovae.
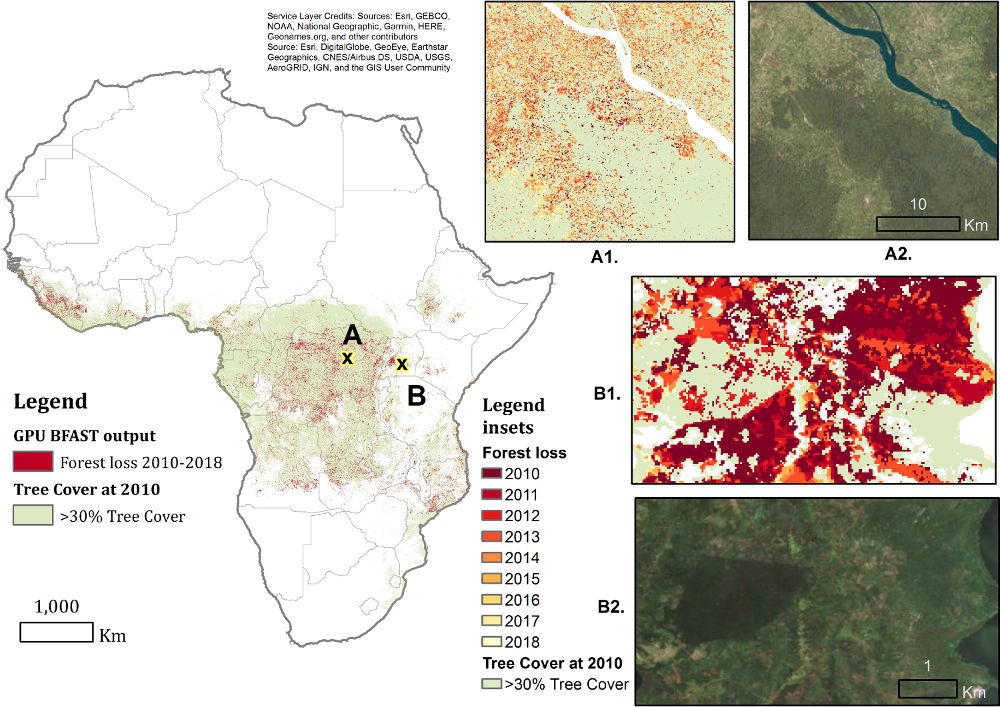 The field of remote sensing is another field that is faced with massive amounts of data. Together with our project partners, we work on efficiently applying state-of-the-art machine learning models to, e.g., identify changes in satellite time series data.
The field of remote sensing is another field that is faced with massive amounts of data. Together with our project partners, we work on efficiently applying state-of-the-art machine learning models to, e.g., identify changes in satellite time series data.
- Brandt, M., Tucker, C., Kariryaa, A., Rasmussen, K., Abel, C., Small, J., Chave, J., Rasmussen, L., Hiernaux, P., Diouf, A., Kergoat, L., Mertz, O., Igel, C., Gieseke, F., Schöning, J., Li, S., Melocik, K., Meyer, J., SinnoS, , Romero, E., Glennie, E., Montagu, A., Dendoncker, M., & Fensholt, R. (2020). An unexpectedly large count of non-forest trees in the Sahara and Sahel. Nature, 2020. (Accepted)
- Oehmcke, S., Thrysøe, C., Borgstad, A., Salles, M., Brandt, M., & Gieseke, F. (2019). Detecting Hardly Visible Roads in Low-Resolution Satellite Time Series Data. In Proceedings of the International Conference on Big Data, Los Angeles, USA, 2403–2412.
- Gieseke, F., Bloemen, S., Bogaard, C., Heskes, T., Kindler, J., Scalzo, R., Ribeiro, V., Roestel, J., Groot, P., Yuan, F., Möller, A., & Tucker, B. (2017). Convolutional Neural Networks for Transient Candidate Vetting in Large-Scale Surveys. Monthly Notices of the Royal Astronomical Society (MNRAS), 472(3), 3101–3114.
- Kremer, J., Stensbo-Smidt, K., Gieseke, F., Pedersen, K., & Igel, C. (2017). Big Universe, Big Data: Machine Learning and Image Analysis for Astronomy. IEEE Intelligent Systems, 32(2), 16–22.
 The energy transition that takes place in many parts of the world has led to a shift towards renewable energy sources such as wind or solar power plants. On the one hand, such environment-friendly resources depict very promising and, in the context of the climate change, necessary alternatives to conventional fossil energy sources. On the other hand, solar and wind energy depict volatile resources and the amount of produced energy heavily. In addition, storing energy is still a lossy and expensive process. Since energy production and consumption have to be balanced at all times, additional efforts have to be made to ensure a stable integration of these new resources into the overall energy grid. In the past years, this has led to the concept of smart grids, which describes the interconnectedness, monitoring, and control of the individual components of the energy grid. Our work also involves the application of machine learning models in this context to, e.g., estimate the energy consumption of households/cities.
The energy transition that takes place in many parts of the world has led to a shift towards renewable energy sources such as wind or solar power plants. On the one hand, such environment-friendly resources depict very promising and, in the context of the climate change, necessary alternatives to conventional fossil energy sources. On the other hand, solar and wind energy depict volatile resources and the amount of produced energy heavily. In addition, storing energy is still a lossy and expensive process. Since energy production and consumption have to be balanced at all times, additional efforts have to be made to ensure a stable integration of these new resources into the overall energy grid. In the past years, this has led to the concept of smart grids, which describes the interconnectedness, monitoring, and control of the individual components of the energy grid. Our work also involves the application of machine learning models in this context to, e.g., estimate the energy consumption of households/cities.
Weakly-Supervised Learning
 A variety of techniques can be found in the fields of data mining and machine learning. A common approach is to “adapt” existing techniques to the specific properties of an application at hand in order to improve the models’ performances. Previous and current research projects focus on the adaptation of standard classification and regression tools to make them more amenable for data scenarios with, e. g. (a) a few labeled instances or (b) many training data patterns in low-dimensional feature spaces (both cases can be very challenging from a data analysis perspective). An example of such an adaptation are semi-supervised learning schemes, which can easily be illustrated by means of email spam filters: For the generation of such filters, one usually considers the previous user behavior via emails labeled as “spam” or “no spam”. In case many such labeled training instances are given, one can generate high-quality models that can effectively classify incoming emails. The generation of a sufficiently large training set, however, can be very time- and cost-intensive (requires, e. g., manual interactions by the user). In contrast, unlabeled data (e. g., emails that are stored on the server, possibly from other users) can often be obtained without much additional effort. Semi-supervised learning schemes aim at incorporating these additional data instances into the learning process to improve the classification performance of such filters.
A variety of techniques can be found in the fields of data mining and machine learning. A common approach is to “adapt” existing techniques to the specific properties of an application at hand in order to improve the models’ performances. Previous and current research projects focus on the adaptation of standard classification and regression tools to make them more amenable for data scenarios with, e. g. (a) a few labeled instances or (b) many training data patterns in low-dimensional feature spaces (both cases can be very challenging from a data analysis perspective). An example of such an adaptation are semi-supervised learning schemes, which can easily be illustrated by means of email spam filters: For the generation of such filters, one usually considers the previous user behavior via emails labeled as “spam” or “no spam”. In case many such labeled training instances are given, one can generate high-quality models that can effectively classify incoming emails. The generation of a sufficiently large training set, however, can be very time- and cost-intensive (requires, e. g., manual interactions by the user). In contrast, unlabeled data (e. g., emails that are stored on the server, possibly from other users) can often be obtained without much additional effort. Semi-supervised learning schemes aim at incorporating these additional data instances into the learning process to improve the classification performance of such filters.
- Ko, V., Oehmcke, S., & Gieseke, F. (2019). Magnitude and Uncertainty Pruning Criterion for Neural Networks. In Proceedings of the IEEE International Conference on Big Data, Los Angeles, USA, 2317–2326.
- Gieseke, F. (2015). An Efficient Many-Core Implementation for Semi-Supervised Support Vector Machines. In Pardalos, P., Pavone, M., Farinella, G., & Cutello, V. (Eds.), Machine Learning, Optimization, and Big Data — First International Workshop. Lecture Notes in Computer Science: Vol. 9432, pp. 145–157, Springer.
- Gieseke, F., Airola, A., Pahikkala, T., & Kramer, O. (2014). Fast and simple gradient-based optimization for semi-supervised support vector machines. Neurocomputing, 123, 23–32.
- Gieseke, F., Pahikkala, T., & Igel, C. (2013). Polynomial Runtime Bounds for Fixed-Rank Unsupervised Least-Squares Classification. In Ong, C., & Ho, T. (Eds.), Asian Conference on Machine Learning, ACML 2013, Canberra, ACT, Australia, November 13-15, 2013 (pp. 62–71). JMLR Workshop and Conference Proceedings: Vol. 29. JMLR.org.